Rui Liu, Xiaochen Peng, Xiaoyu Sun, Win-San Khwa, Xin Si, Jia-Jing Chen, Jia-Fang Li, Meng-Fan Chang, and Shimeng Yu. 2018. Parallelizing SRAM arrays with customized bit-cell for binary neural networks. In Proceedings of the 55th Annual Design Automation Conference (DAC ’18). Association for Computing Machinery, New York, NY, USA, Article 21, 1–6. DOI:https://doi.org/10.1145/3195970.3196089.
The paper is here
Abstract first:
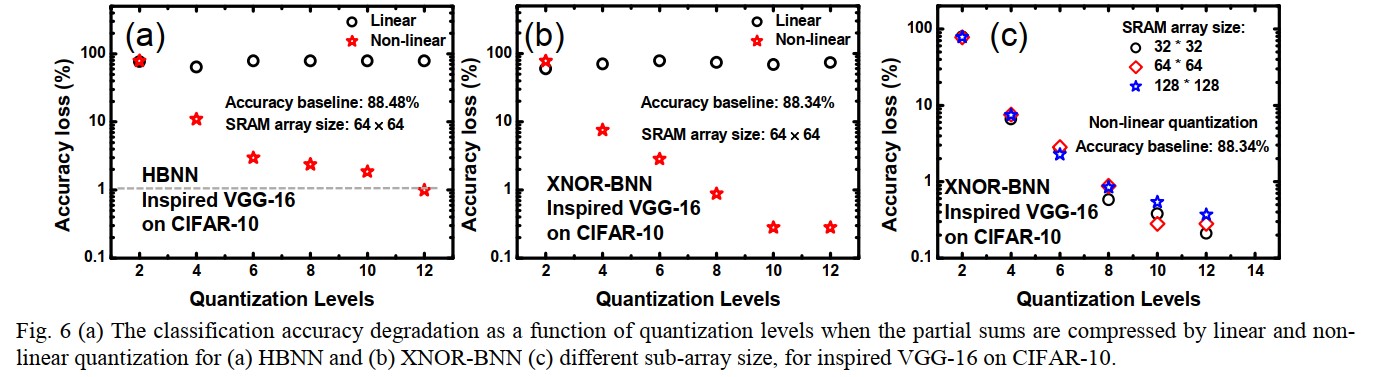
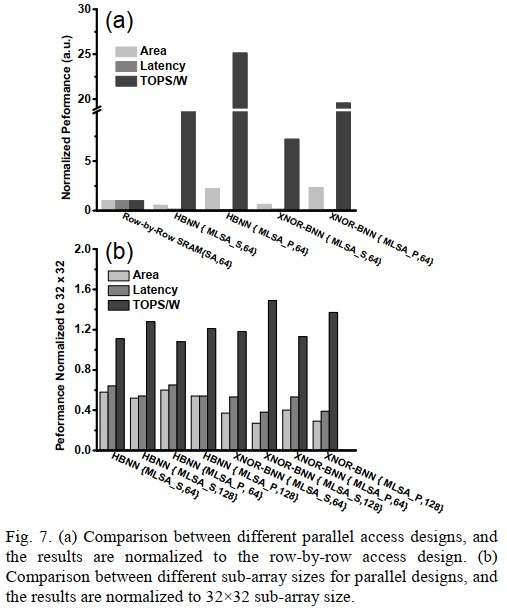
Recent advances in deep neural networks (DNNs) have shown Binary Neural Networks (BNNs) are able to provide a reasonable accuracy on various image datasets with a significant reduction in computation and memory cost. In this paper, we explore two BNNs: hybrid BNN (HBNN) and XNOR-BNN, where the weights are binarized to +1/-1 while the neuron activations are binarized to 1/0 and +1/-1 respectively. Two SRAM bit cell designs are proposed, namely, 6T SRAM for HBNN and customized 8T SRAM for XNOR-BNN. In our design, the high-precision multiply-and-accumulate (MAC) is replaced by bitwise multiplication for HBNN or XNOR for XNOR-BNN plus bit-counting operations. To parallelize the weighted sum operation, we activate multiple word lines in the SRAM array simultaneously and digitize the analog voltage developed along the bit line by a multi-level sense amplifier (MLSA). In order to partition the large matrices in DNNs, we investigate the impact of sensing bit-levels of MLSA on the accuracy degradation for different sub-array sizes and propose using the nonlinear quantization technique to mitigate the accuracy degradation. With 64×64 sub-array size and 3-bit MLSA, HBNN and XNOR-BNN architectures can minimize the accuracy degradation to 2.37% and 0.88%, respectively, for an inspired VGG-16 network on the CIFAR-10 dataset. Design space exploration of SRAM based synaptic architectures with the conventional row-by-row access scheme and our proposed parallel access scheme are also performed, showing significant benefits in the area, latency and energy-efficiency. Finally, we have successfully taped-out and validated the proposed HBNN and XNOR-BNN designs in TSMC 65 nm process with measured silicon data, achieving energy-efficiency >100 TOPS/W for HBNN and >50 TOPS/W for XNOR-BNN.
Contributions:
XNOR-BNN complementary with costomized SRAM
Peripheral circuits which allow parallel access for SRAM
Low accuracy degration and high energy saving
Background:
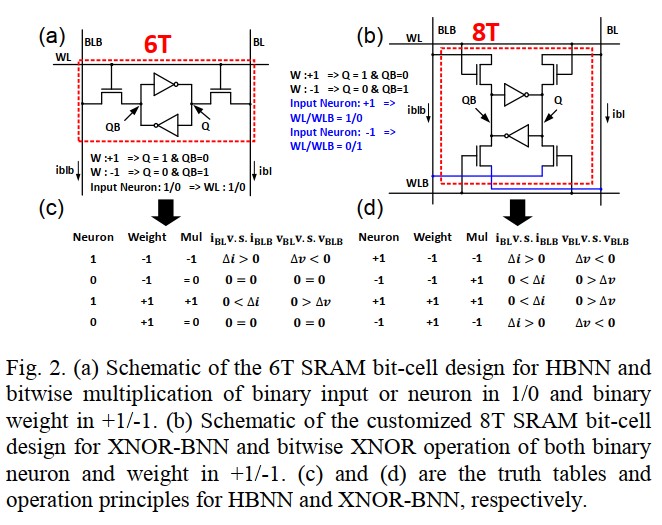
HBNN (proposed)
Feature:
Weights: +1 / -1
Activations: 0 / 1
SRAM Cell
Directly refer to the explicit figure:
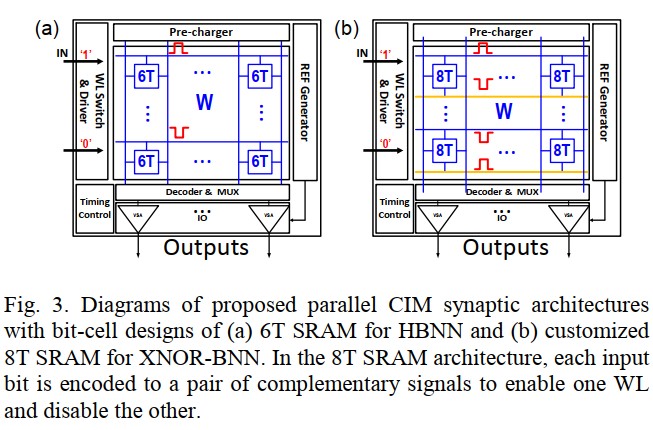
Parallel Architecture
All the cells in the same column are opened by WLs. Currents are accumulated at BLs, and the MAC operation is implemented.
Experiments & Results
Accuracy
Performance
Chip

文档信息
- 本文作者:Yilong Zhao
- 本文链接:https://xiaoke0515.github.io/2020/08/03/2_SRAM_BNN/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)